对于集群联邦而言,多集群调度无疑是最核心的能力之一,甚至很长时间Karmada被认为是一个多集群的调度器,这也侧面反映了调度的重要性。
在多云的时代,应用的调度可以分为两步,首先将应用调度至某个集群/集群组,然后由集群内的调度器选择一个合适的节点,其中后一步由Kubernetes原生的调度器负责。
就像Kubernetes将Pod调度至节点上一样,KubeFed(上游社区的集群联邦项目)引入了工作负载的联邦API,并由一个全局的调度器将它调度至符合条件的集群。
Federated API区别于Kubernetes原生的API,包含以下三个部分:
- Template: 定义跨集群应用的一个通用资源模板
- Placement: 定义资源应调度至哪个集群
- Overrides: 定义应用在不同集群的差异化配置
KubeFed一定程度上解决了多云容器编排的几个核心挑战,但是也存在一些弊端,其一是引入了Federated API,非原生API不论是对用户的学习成本还是对现有架构的改造成本都很大,进而导致用户从单集群迁移到多集群的成本较大, 其二是API不够通用,特定的原生API存在一类对应的联邦API(例如deployment即有federateddeployments),一方面在资源种类较多时会导致控制面非常臃肿,另一方面对CRD的支持不够友好。
Karmada针对KubeFed的上述问题做了大刀阔斧的改革,通过关注点分离的设计思想将Federated API分离为三个独立的职责单一的API。PropagationPolicy表示用户的多集群调度策略,OverridePolicy表示应用在多集群的差异化配置策略, 借助Kubernetes原生API的能力,用户可以轻松从单集群架构转换为多集群架构。为了适应拆分的API,Karmada引入了全新的API workflow来串联内部流程:
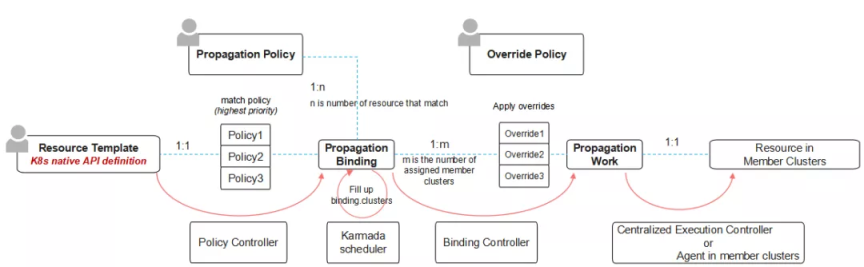
其中比较重要的是引入了ResourceBinding和Work对象:
- ResourceBinding: Karmada调度器实际进行调度的对象,通过OwnerReference与资源模板关联,同时Spec内包含模板和Placement的信息,是一个串联流程的中间产物。
- Work: 成员集群的资源对象在控制面的映射,不同集群的对象通过命名空间隔离,是对象决定分发的集群后应用OverridePolicy的最终产物。
在解决了用户的迁移问题后,下一步需要解决的问题就是如何解决用户多样化的调度需求。
以下简单列举一些常用的调度策略:
- 指定集群名调度
- 指定集群的label调度
- 通过集群的taint/toleration调度
- 每个region/provider/zone选取若干个集群调度
- 随机取若干个集群调度
- 选取资源余量最多的集群调度
- 选取资源价格最低的公有云集群进行调度
- 调度至本地IDC集群,资源殆尽后调度至公有云集群
- ….
考虑到同一个应用可以在多个集群中拆分Pod实例,拆分的策略也同样有不同的需求。
- 静态比例拆分
- 根据资源余量按比例分配
- 尽可能聚合到一个资源最多的集群
- ….
相比于单集群内Pod的调度流程,多集群的调度多了特有的两步,其一是选取集群,其二是分配实例。Karmada的调度流程和调度框架可以参考:https://karmada.io/docs/developers/customize-karmada-scheduler 基于上述的不同点,多集群调度也有很多挑战。
-
1:1 -> 1:n Pod在调度时只需选择一个最适合的节点,而多集群调度时通常需要选择一些合适的集群,其中的计算复杂度会大大提升。 区分于将节点根据打分结果的线性排序,多集群调度由于一些物理属性的差异天然存在集群组的概念,在调度选取最优的某些集群时可能会有多层的排序。
-
价格敏感型的调度 多云结合FinOps的一种实践,按照公有云的资源价格来选择不同厂商的集群。
-
节点感知型的调度 节点是Pod实际运行的资源实体,例如当我们想选取资源余量最多的集群调度时,我们需要考虑集群的资源总量,如果把每个节点的资源机械相加,可能存在总量大但每个节点资源少的现象,那么实际上这个集群仍是不可调度的,因此为了提升调度的精准度,集群需要能感知到节点的资源分布情况。 类似的情况还有很多,联邦层选择了某个集群进行调度,但是kube-scheduler仍有调度失败的可能性,症结主要在于集群里存放所有节点的详细信息成本较大,调度时也无法做到对某个集群进行模拟调度。除此之外,节点的故障可以从底层的虚拟机或物理机反映上来,但如何反映集群局部的故障, 不仅仅是K8s的控制面异常,是一个很有难度的挑战。
-
重调度、抢占、依赖分发等高级调度特性 上述想解决的问题是如何提升首次调度的准确性,另一种可行的思路是在首次调度没有成功运行起工作负载的情况下提供一次重调度的机会,这种思路可行的前提是工作负载最终没有运行起来的原因可以通过跨集群调度来解决,Karmada的Descheduler以及故障迁移都是类似的尝试。 除了运行失败的场景,某些场景下用户希望能主动进行新的调度尝试,例如希望通过策略的更新/抢占来更改某个工作负载的策略。此外,调度策略不变,但集群状态发生改变时,同一个策略的调度结果可能发生变化,这时用户也会有重调度的需求。
-
有状态应用的拆分调度