KubeAdmiral是字节跳动开源的新一代多集群编排调度引擎,基于KubeFed演进而来,解决了KubeFed在生产落地中遇到的问题:
- 资源利用率低,KubeFed的副本调度策略RSP不够灵活,无法灵活应对集群资源的变化
- 变更不够平滑,扩缩容时经常出现实例分布不均的现象,导致容灾能力下降
- 调度语意局限,只对无状态类资源有较好的支持,调度扩展性差
- 接入成本高,不支持原生API
KubeAdmiral架构图如下:
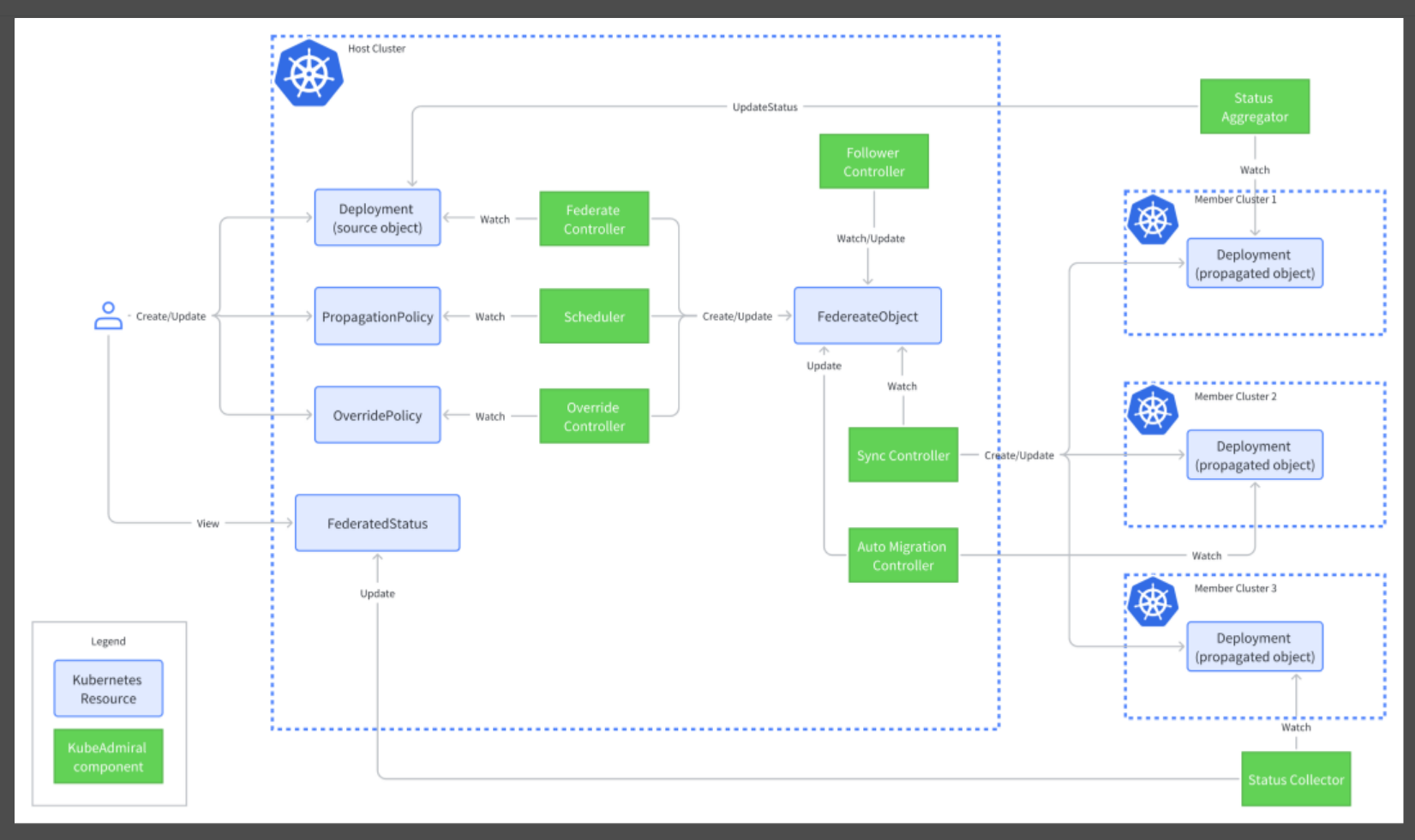
从KubeAdmiral的架构图发现,KubeAdmiral保留了KubeFed的整体架构,并通过拆分API的手段简化用户学习成本,通过新增组件的形式扩展了KubeFed的能力。
原生API
区别于Karmada,KubeAdmiral将federated API作为内部串联的对象,用户在提交原生API、pp、op后,由Federated controller来生成联邦对象,供其他控制器使用。 KubeAdmiral继承了KubeFed的FederatedTypeConfig API,本质上维护了原生资源和联邦资源的映射关系。每一种FTC都会有对应的几种subController,Federated controller就是其中之一。当一个新的FTC创建后,对应的Federated controller会启动,并监听FTC解析出来的原生资源和联邦资源。以Deploy与Fdeploy为例,当Federated controller检测到deploy时,会同步检查控制面是否存在fdeploy,若发现Not Found,它会创建对应的fdeploy。
状态收集
KubeAdmiral提供了两条反映多集群资源状态的路径:
- 从成员集群的状态汇聚到联邦资源状态对象上 以deployment为例,多集群的状态会汇聚至federateddeploymentstatus对象,由status-collector组件完成:
apiVersion: types.kubeadmiral.io/v1alpha1
clusterStatus:
- clusterName: kubeadmiral-member-1
collectedFields:
metadata:
creationTimestamp: "2023-07-12T10:14:18Z"
spec:
replicas: 1
status:
availableReplicas: 1
conditions:
- lastTransitionTime: "2023-07-12T10:15:34Z"
lastUpdateTime: "2023-07-12T10:15:34Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2023-07-12T10:14:18Z"
lastUpdateTime: "2023-07-12T10:15:34Z"
message: ReplicaSet "echo-server-65dcc57996" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 1
replicas: 1
updatedReplicas: 1
- clusterName: kubeadmiral-member-2
collectedFields:
metadata:
creationTimestamp: "2023-07-12T10:14:18Z"
spec:
replicas: 3
status:
availableReplicas: 3
conditions:
- lastTransitionTime: "2023-07-12T10:15:51Z"
lastUpdateTime: "2023-07-12T10:15:51Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2023-07-12T10:14:18Z"
lastUpdateTime: "2023-07-12T10:15:51Z"
message: ReplicaSet "echo-server-65dcc57996" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 3
replicas: 3
updatedReplicas: 3
- clusterName: kubeadmiral-member-3
collectedFields:
metadata:
creationTimestamp: "2023-07-12T10:14:18Z"
spec:
replicas: 2
status:
availableReplicas: 2
conditions:
- lastTransitionTime: "2023-07-12T10:15:46Z"
lastUpdateTime: "2023-07-12T10:15:46Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2023-07-12T10:14:18Z"
lastUpdateTime: "2023-07-12T10:15:46Z"
message: ReplicaSet "echo-server-65dcc57996" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 2
replicas: 2
updatedReplicas: 2
kind: FederatedDeploymentStatus
metadata:
annotations:
kubeadmiral.io/aggregated-updated-replicas: "6"
kubeadmiral.io/current-revision: echo-server-6cc5799986
kubeadmiral.io/latest-replicaset-digests: '[]'
creationTimestamp: "2023-07-12T10:13:46Z"
generation: 8
labels:
kubeadmiral.io/propagation-policy-name: policy-all-clusters
name: echo-server
namespace: default
ownerReferences:
- apiVersion: types.kubeadmiral.io/v1alpha1
kind: FederatedDeployment
name: echo-server
uid: 00082beb-3560-4dc9-b0a4-b51a73128496
resourceVersion: "5027"
uid: f2f95fbe-ee33-4041-b5ff-7478de95619a
- 从成员集群的状态汇聚到控制面的原生API,由status-aggregator组件完成,类似Karmada中的Resource Interpreter Framework中的AggregatedStatus接口, 针对特定资源作状态聚合。
多集群调度能力
PropagationPolicy 承载多集群的调度能力,支持的调度策略包括:
- 复制/拆分的实例调度,拆分模式下除了指定权重还支持指定最小/最大实例数
- 调度插件的配置文件
- 根据label过滤集群
- 根据toleration过滤集群
- 限制调度集群的数量
- 依赖分发
- 跨集群故障迁移,以Pod不可调度的时间间隔为触发条件
- 根据集群资源余量分配实例
- 重调度防止实例变化引起震荡
KubeAdmiral的调度过程分为filter、score、select、replicas四个阶段,相较于Karmada,新增了webhook形式的可扩展的插件:
跨集群自动迁移
KubeAdmiral提供了一个针对不可调度的Pod进行自动迁移的能力,由auto-migration-controller负责。 这个控制器会watch成员集群的工作负载,获得工作负载所附生的所有Pod,通过对Pod状态的判断,获得当前可调度的Pod数,即为estimatedCapacity,并写至Federated API的annotation中。 不同工作负载映射到Pod的方法不同,KubeAdmiral通过插件的方式供用户扩展。
调度器在调度实例的时候会考虑estimatedCapacity的当前容量值。调度过程推演,3个集群权重均为1,拆分6个实例,集群1的容量为1个Pod。
集群容量未知,且member1:member2:member3 = 2:2:2,容易得出member1有个unschedulable的Pod。
当前实例:
| member1 replicas | member2 replicas | member3 replicas | currentTotalOkReplicas |
|---|---|---|---|
| 2(1 unschedulable) | 2 | 2 | 5 |
获取集群容量后进行重调度:
第一轮调度
| remaining replicas | member1 replicas | member1 overflow | member2 replicas | member2 overflow | member3 replicas | member3 overflow |
|---|---|---|---|---|---|---|
| 1 | min((6*1+3-1)/3, 1) = 1 | 1 | 2 | 0 | 2 | 0 |
第二轮调度:
| remaining replicas | member1 replicas | member1 overflow | member2 replicas | member2 overflow | member3 replicas | member3 overflow |
|---|---|---|---|---|---|---|
| 0 | min((6*1+3-1)/3, 1) = 1 | 1 | 3 | 0 | 2 | 0 |
最终调度结果为 member1:member2:member3 = 1:3:2。
当currentTotalOkReplicas < desiredTotalReplicas时,做扩容的操作,并将实例扩容给desiredReplicas > currentReplicas的集群。
假设member1、member2、member3集群容量均为1:1:1。
当前实例:
| member1 replicas | member2 replicas | member3 replicas | currentTotalOkReplicas |
|---|---|---|---|
| 1 | 3 | 2 | 3 |
获取集群容量后重调度:
| remaining replicas | member1 replicas | member1 overflow | member2 replicas | member2 overflow | member3 replicas | member3 overflow |
|---|---|---|---|---|---|---|
| 3 | min((6*1+3-1)/3, 1) = 1 | 1 | 1 | 1 | 1 | 1 |
若保留不可调度的实例后,member1:member2:member3 = 2:2:2,若不保留,则是member1:member2:member3 = 1:1:1。